Gibt es obere Grenzen für die TM-Grösse?
Die Anzahl der Segmente in einem Translation Memory ist nur durch den verfügbaren Speicherplatz begrenzt, der dynamisch erweitert werden kann.
Wie wird der Zugang zu TMs verwaltet?
TTN TMS bietet dynamische Zugriffsrechte, die bei Bedarf automatisch gewährt und entzogen werden. Alle Benutzer können auf MultiTerm Online zugreifen; Kunden haben jedoch in der Regel nur Leserechte, während Übersetzer Lese- und Schreibrechte haben. Die Zugriffsrechte werden automatisch überprüft und zugewiesen, wenn ein Auftrag an einen Übersetzer oder Lektor vergeben wird.
Ist es möglich, TM-Felder für besondere Zwecke anzupassen?
Bei juristischen oder technischen Übersetzungen – z. B. von Baunormen – ist es oft sinnvoll, benutzerdefinierte Felder hinzuzufügen, z. B. eine Referenznummer oder einen Link zu dem entsprechenden Artikel oder der Norm. In solchen Fällen muss die Struktur des Translation Memory um benutzerdefinierte Pflichtfelder erweitert werden.
Trados GroupShare unterstützt Translation Memorys mit umfangreichen Metadaten. Jeder TM-Eintrag enthält das Quellsegment, das Zielsegment und eine beliebige Anzahl von benutzerdefinierten Feldern, die von der Organisation festgelegt werden. Diese benutzerdefinierten Felder werden von der GroupShare-Schnittstelle und den APIs vollständig unterstützt: Sie können über Feldvorlagen erstellt, im TM-Editor angezeigt und bearbeitet sowie als Filter- oder Suchparameter verwendet werden.
Wie wird die Suche in Translation Memorys durchgeführt?
Wie werden „exakte Übereinstimmung“ und „unscharfe Übereinstimmung“ gehandhabt, und wie wird sichergestellt, dass die Suche in allen Sprachen korrekt funktioniert?
Die Trados GroupShare Server‑-basierte Translation-Memory-Komponente unterstützt sowohl exakte‑-Match- als auch Fuzzy‑-Match-Suchmodi für die Segment-Suche vollständig. Die exakte Suche findet nur 100% identische Quellensegmente, während die unscharfe Suche ähnliche Segmente zusammen mit einer Ähnlichkeitsbewertung zurückgibt. Die TM-Suchmaschine verwendet robuste Fuzzy‑-Matching-Algorithmen, um den prozentualen Anteil der Übereinstimmungen zu berechnen, der angibt, wie sehr ein neues Segment mit einer bestehenden Übersetzungseinheit übereinstimmt. Dies gewährleistet umfassende und genaue Suchergebnisse, da auch Teilübereinstimmungen erkannt und mit ihrer Relevanzbewertung angezeigt werden.
Alle Pflichtfelder und Metadaten, die mit jeder Übersetzungseinheit verbunden sind, sind in den TM-Suchergebnissen verfügbar. Jeder Treffer zeigt das Quell- und Zielsegment zusammen mit den erforderlichen Metadatenfeldern an, einschliesslich der als obligatorisch gekennzeichneten benutzerdefinierten Felder und der Standard-Systemfelder wie Erstellungsdatum oder Autor. Für alle vom System unterstützten Sprachen gelten dieselben Suchmechanismen, so dass ein einheitliches Verhalten bei mehrsprachigen Inhalten gewährleistet ist.
Wie erkennt TTN TMS bereits übersetzte Segmente?
TTN TMS erkennt automatisch bereits übersetzte Segmente und schlägt sie zur Wiederverwendung vor, sobald ein passendes Quellsegment geöffnet wird. Das System findet sowohl exakte als auch unscharfe Übereinstimmungen im TM, präsentiert jeden Vorschlag mit kontextuellen Details und hebt Unterschiede bei Teilübereinstimmungen hervor, so dass der Übersetzer problemlos die bevorzugte Übersetzung auswählen und einfügen kann, die eindeutig als aus dem TM stammend gekennzeichnet ist.
- Automatisches Einfügen von Übereinstimmungen: Das vorgeschlagene System erkennt automatisch alle bereits übersetzten Segmente im TM (sowohl exakte 100%-Matches als auch unscharfe Teilmatches). Wenn ein Übersetzer ein neues Quellsegment öffnet, wird das TM durchsucht und die am besten passende Übersetzung sofort in das Zielsegment eingefügt. Dadurch wird sichergestellt, dass die Übersetzer vorhandene Übersetzungen so weit wie möglich wiederverwenden, ohne dass für jedes Segment manuell nachgeschlagen werden muss.
- Durchsuchen mit mehreren Übereinstimmungen: Wenn für ein bestimmtes Quellensegment mehr als eine TM-Übereinstimmung gefunden wird, zeigt die Schnittstelle alle Übereinstimmungen (zusammen mit ihren prozentualen Anteilen) als Referenz für den Benutzer an. Der Übersetzer kann diese Vorschläge einfach durchsuchen und sich für einen davon entscheiden. So listet das System beispielsweise im Bereich Übersetzungsergebnisse Übereinstimmungen auf und ermöglicht es dem Benutzer, eine alternative Übereinstimmung anstelle der am höchsten eingestuften Übereinstimmung einzufügen. Dies gibt dem Benutzer die volle Kontrolle über die Auswahl der bevorzugten Übersetzung, wenn mehrere Optionen vorhanden sind.
- Sichtbarkeit der Metadaten anpassen: Für jedes TM-Ergebnis liefert das System zusätzliche Kontext- und Metadaten über die Übereinstimmung. Der Übersetzer kann Informationen wie das TM, aus dem der Treffer stammt, und andere Attribute wie das Originaldokument oder den Dateinamen sehen, falls vorhanden. Diese Metadaten werden neben dem Treffereintrag angezeigt und helfen den Nutzern, die Herkunft und Zuverlässigkeit jedes Vorschlags zu beurteilen.
- Hervorgehobene Unterschiede bei Teilübereinstimmungen: Wenn eine gespeicherte Übersetzung nur teilweise mit dem neuen Quellsegment übereinstimmt, hebt das System alle Unterschiede zwischen dem Ausgangstext und dem TM-Vorschlag deutlich hervor. Alle Wörter oder Sätze, die sich unterscheiden, werden in der Gegenüberstellung angegeben (z. B. indem hinzugefügter Text in einer Farbe unterstrichen und gestrichener Text in einer anderen Farbe durchgestrichen wird). Auf diese Weise kann der Übersetzer sofort erkennen, welche Änderungen erforderlich sind, da die Unterschiede in einer Art „Änderungsverfolgung“ dargestellt werden, damit sie leicht zu erkennen sind.
- Eindeutige Kennzeichnung der eingefügten TM-Inhalte: Vorgefüllte oder aus TM-Matches eingefügte Segmente werden in der Bearbeitungsumgebung sichtbar markiert. Ein Symbol oder Abzeichen in der Statusspalte des Segments zeigt beispielsweise an, dass der Inhalt aus einer TM-Übereinstimmung stammt, und gibt sogar den Prozentsatz der Übereinstimmung an. Auf diese Weise können Übersetzer und Korrektoren sofort erkennen, welche Zielsegmente aus dem TM übernommen wurden (und auf welcher Match-Ebene), was für Transparenz sorgt. Sobald der Übersetzer das Segment bearbeitet oder bestätigt, wird der Indikator entsprechend aktualisiert, um anzuzeigen, dass die Übersetzung überprüft wurde, wobei die ursprünglichen Match-Informationen als Referenz erhalten bleiben.
Alle diese Funktionen werden von der Translation-Memory-Komponente von TTN TMS vollständig unterstützt, so dass frühere Übersetzungen effizient genutzt werden können und die Übersetzer gleichzeitig die volle Kontrolle und Transparenz haben. Dieser TM-Matching-Mechanismus steigert nicht nur die Produktivität durch die Wiederverwendung vorhandener Übersetzungen, sondern bietet den Übersetzern auch klare Informationen und Optionen, um die Qualität und Konsistenz der Übersetzungen zu gewährleisten.
Wie integriert TTN TMS maschinelle Übersetzung mit TM?
TTN TMS kombiniert nahtlos fortschrittliche maschinelle Übersetzung (MT), Translation Memory (TM) und Terminologieverwaltung in einem leistungsstarken Workflow. Dieser integrierte Ansatz gibt Ihnen die Flexibilität, das Beste aus von Menschen geprüften Übersetzungen und von KI generierten Vorschlägen zu nutzen. Das Ergebnis ist eine qualitativ hochwertigere Ausgabe mit weniger Aufwand – und das alles durch intelligente Automatisierung, die Ihre Projekte beschleunigt, ohne die Genauigkeit zu beeinträchtigen.
- Automatische MT-Vorschläge, wenn kein TM übereinstimmt: Wenn für ein neues Segment kein TM-Match vorhanden ist, liefert TTN TMS automatisch einen Vorschlag für eine maschinelle Übersetzung. Dieser Vorschlag kann direkt in den Zieltext eingefügt oder Ihnen zur Überprüfung angeboten werden, so dass der Übersetzer nie mit einer leeren Seite beginnt. Selbst wenn Ihr Translation Memory keinen Eintrag hat, haben Sie immer einen ersten Übersetzungsentwurf parat – das spart Zeit und reduziert die manuelle Arbeit.
- MT-Vorschläge unter Einbezug von TM-Treffern: TTN TSM stützt sich nicht nur auf eine einzige zentrale Referenzquelle. Selbst wenn eine unscharfe oder exakte Übereinstimmung im TM gefunden wird, kann das System einen parallelen MÜ-Vorschlag abrufen und ihn neben dem TM-Ergebnis anzeigen. Dieser Seite-an-Seite-Vergleich ermöglicht es den Linguisten, die beste Option zu wählen oder sogar Ideen aus beiden Vorschlägen zu kombinieren. Durch die Kombination von MT- und TM-Ergebnissen erhöht unsere Plattform die Übersetzungsqualität und -flexibilität, so dass Sie von früheren Übersetzungen profitieren und gleichzeitig die neuesten Verbesserungen der KI-Übersetzung nutzen können.
- Integration mit benutzerdefinierten MT-Engines (Azure, ChatGPT, DeepL, etc.): Die KI-Plattform ist engine- und herstellerunabhängig konzipiert. TTN TSM integriert führende MÜ-Anbieter und generative KI-Plattformen, darunter Microsoft Azure Translator, DeepL und GPT-basierte Engines wie ChatGPT. Es können sogar benutzerdefinierte trainierte Modelle über die API eingebunden werden. Diese Flexibilität bedeutet, dass Sie Ihre bevorzugte maschinelle Übersetzungsmaschine einsetzen können, um qualitativ hochwertigere Vorschläge zu erhalten. Wenn neue MÜ-Technologien auftauchen, können sie nahtlos integriert werden, was den Übersetzungsworkflow zukunftssicher macht und sicherstellt, dass der Auftraggeber immer Zugang zu erstklassigen, auf Ihre Bedürfnisse zugeschnittenen KI-Übersetzungen haben.
- Konversationelle KI für Kontext und Terminologie: Die innovative konversationelle KI-Schicht von TTN verleiht der Übersetzungsproduktivität eine neue Dimension. Herkömmliche Translation-Memory-Systeme und Terminologiedatenbanken arbeiten oft nicht optimal zusammen. So kann es vorkommen, dass ein partieller (unscharfer) TM-Match nicht automatisch die richtigen Begriffe aus dem gewünschten Glossar enthält. Die von TTN entwickelte GPT-gestützte Konversations-KI schliesst diese Lücke. Es kombiniert auf intelligente Weise unscharfe Übereinstimmungen aus dem TM mit der von Ihnen genehmigten Terminologie im Kontext und generiert so einen verfeinerten Übersetzungsvorschlag, der sowohl den Kontext des Satzes als auch Ihre spezifische Begriffswahl berücksichtigt.
Durch die Nutzung der fortschrittlichen GPT-basierten KI in TTN TSM kann das System ein Segment zusammen mit allen relevanten TM-Fragmenten und erforderlichen Glossarbegriffen analysieren und dann eine flüssige Übersetzung erstellen, die diese Elemente nahtlos einbezieht. Das bedeutet, dass die Übersetzung nicht einfach nur eine generische Maschinenausgabe ist, sondern auf der Grundlage früherer Übersetzungen und der bevorzugten Terminologie Ihres Unternehmens mit Hilfe einer intelligenten KI-gesteuerten Eingabeaufforderung erstellt wird. Die KI berücksichtigt Nuancen, den Kontext und die Hinweise aus Ihren Daten, um ein Ergebnis zu liefern, das herkömmliche MÜ-Maschinen in puncto Genauigkeit und Konsistenz übertrifft.
Die konversationelle KI-Schicht eliminiert effektiv das übliche Hin und Her bei der Korrektur von Terminologie oder der Nachbearbeitung von Fuzzy-Matches. Die Übersetzer erhalten qualitativ hochwertige Übersetzungsentwürfe, die bereits Ihren Glossaren und Stilrichtlinien entsprechen, wodurch sich der Bearbeitungsaufwand verringert. Kurz gesagt, die MT-TM-Integration von TTN TSM – unterstützt durch eine intelligente KI-Schicht – stellt sicher, dass Sie Übersetzungen erhalten, die von Anfang an mit Ihrer Markensprache und Terminologie übereinstimmen, und beschleunigt gleichzeitig die Lieferung. Es vereint das Beste aus Translation Memory, maschineller Übersetzung und KI-Innovation und ermöglicht es dem Mitarbeiter-Team, bessere Übersetzungen in kürzerer Zeit zu liefern.
Wie werden die TMs verwaltet?
Das Übersetzungsmanagementsystem bietet umfassende Funktionen für die Verwaltung von Translation Memories und Termbanken. Es kombiniert automatisierte Prozesse mit der Kontrolle durch den Administrator, um ein effektives und flexibles Ressourcenmanagement zu gewährleisten. Die wichtigsten Aspekte sind:
Das System übernimmt automatisch die Einrichtung von Translation Memorys und Termbanken auf der Grundlage von Projektsprachenpaaren. Wenn ein Projekt eine bisher unbenutzte Kombination von Ausgangs- und Zielsprache umfasst, generiert das System ein neues TM und einen neuen TB unter Verwendung von vordefinierten Vorlagen und Parametern, wodurch eine spezielle Ressource für dieses Sprachenpaar gewährleistet wird. Wenn bereits ein entsprechendes TM oder TB für das gewünschte Sprachenpaar vorhanden ist, verwendet das System die vorhandene Ressource wieder, anstatt ein Duplikat zu erstellen.
Wie kontrollieren die Übersetzungsmanager die Termbanken?
Administratoren oder Übersetzungsmanager haben die volle Kontrolle über alle Translation Memorys und Termbanken. Sie können TMs und TBs manuell erstellen, ändern oder löschen und deren Struktur (z. B. durch Hinzufügen oder Ändern von Feldern und Metadaten) und Inhalt anpassen. Das System unterstützt auch den Import und Export von TM/TB-Daten zu Sicherungs-, Migrations- oder Integrationszwecken, was dem Unternehmen Flexibilität bei der Verwaltung der linguistischen Ressourcen verleiht.
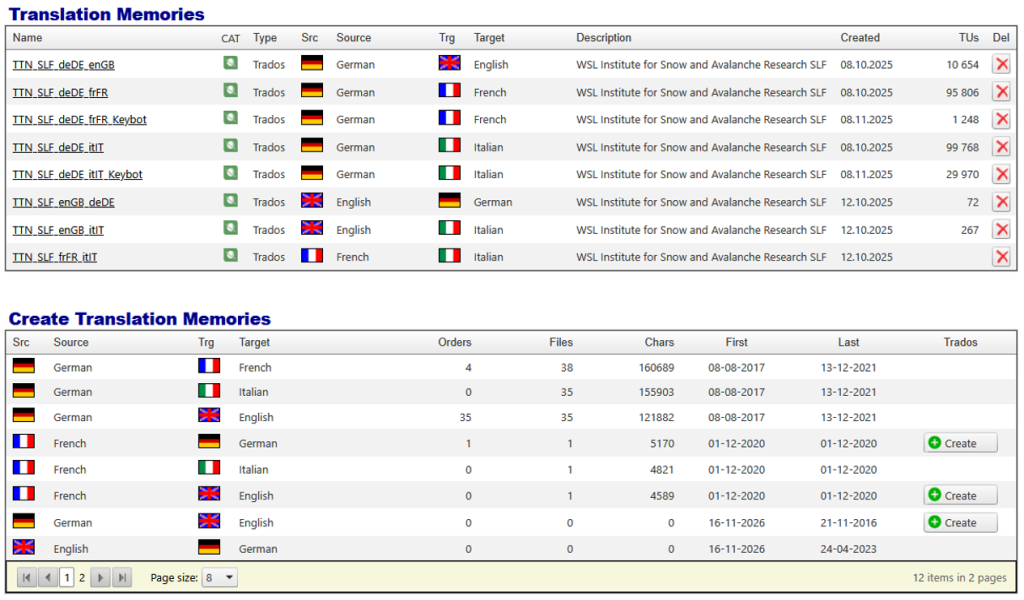
Abbildung 1: TM manuell auf der Grundlage einer vordefinierten Vorlage erstellen
Strukturelle Anpassungen über GroupShare: Wenn ein Translation Memory erweiterte strukturelle Änderungen erfordert, die über die Standardvorlage hinausgehen (z. B. das Hinzufügen benutzerdefinierter Felder), kann ein Übersetzungsmanager oder Systemoperator eine direkte Verbindung zu dem zugrunde liegenden TM-Server herstellen, um diese Änderungen vorzunehmen. Dieser Ansatz stellt sicher, dass spezielle Konfigurationen auch dann implementiert werden können, wenn dies den Einsatz von Tools erfordert, die über die Standard-Webschnittstelle hinausgehen.
Abbildung 2: TM mit speziellem Feld direkt auf dem GroupShare Server erstellen
Zusammenfassend lässt sich sagen, dass das System die Verwaltung von Translation Memorys und Termbanken automatisch übernimmt, indem es Ressourcen je nach Bedarf für neue Sprachkombinationen erstellt oder wiederverwendet, während Administratoren bei Bedarf eine detaillierte Überwachung und Anpassung vornehmen können. Dadurch wird sichergestellt, dass Unternehmenskunden sowohl von der Effizienz durch Automatisierung als auch von der Flexibilität durch die Kontrolle des Administrators beim TM- und TB-Management profitieren.
In einer TTN TMS-Umgebung mit SDL Trados GroupShare Integration stehen Übersetzungssegmente und terminologische Einträge, die von einem Benutzer in einem gemeinsam genutzten Translation Memory (TM) oder einer Termbank gespeichert wurden, anderen autorisierten Benutzern sofort zur Verfügung. GroupShare ist eine serverbasierte Lösung für die Zusammenarbeit, die die TMs und Terminologiedatenbanken zentralisiert. Wenn ein Teammitglied ein Segment bestätigt oder einen Begriff hinzufügt, wird dieser sofort für alle anderen Benutzer aktualisiert, die über die entsprechenden Zugriffsrechte verfügen. Das bedeutet, dass die neuesten Übersetzungen und die neueste Terminologie dem gesamten Team ohne Verzögerung zur Verfügung stehen und eine echte Zusammenarbeit in Echtzeit ermöglichen.
GroupShare erreicht dies durch seine zentralisierte TM- und Terminologiedatenbank. Sobald ein Übersetzer eine neue Übersetzungseinheit oder einen Begriff speichert, wird diese/r auf dem Server abgelegt und kann sofort von anderen abgerufen werden. Wenn beispielsweise ein Übersetzer eine neue Übersetzung für ein Segment bestätigt, sieht jeder Kollege, der später auf denselben Ausgangstext stösst, die Übersetzung sofort als 100%ige Übereinstimmung mit dem TM. Wenn ein Benutzer einen Begriff zur gemeinsamen Termbank hinzufügt, wird dieser Begriff sofort als anerkannter Begriff in seinem Übersetzungstool angezeigt. Durch diese sofortige Synchronisierung wird sichergestellt, dass alle Teammitglieder stets mit den aktuellsten Übersetzungen und der vereinbarten Terminologie arbeiten.
Durch die Bereitstellung von Echtzeit-Updates für die gemeinsam genutzten TMs und Termbanken trägt GroupShare zur Wahrung der Konsistenz bei und erleichtert die Teamarbeit. Alle Benutzer arbeiten mit demselben aktuellen Bestand an genehmigten Übersetzungen und Begriffen in einer sicheren, einheitlichen Umgebung. Dies verbessert nicht nur die allgemeine Konsistenz und Qualität der Übersetzungen, sondern macht auch die Zusammenarbeit zwischen Übersetzern und Lektoren viel effizienter, da jeder die neuesten bestätigten Segmente und die neueste Terminologie nutzt.