Translation with all major AI Translation Services
TTN TMS offers three levels of automatic translation in its workflow:
- Full post-editing
- Light post-editing
- Fully automatic translation
The files are systematically translated by multiple AI translation providers.
Figure 1: Parallel translation using all major AI translation services
The translated outputs are compared with each other, and the system produces several comparison metrics to evaluate which provider performs best. The automatic translations are run both with and without using translation memory (TM) and termbase data. This allows evaluation of each translation provider’s quality and helps determine which LLM (large language model) works best. It also helps determine the added value of data provided by GroupShare. Last but not least, this approach can even detect whether a translator performed the translation themselves or used an AI tool. Each AI provider has its own distinct “DNA” or linguistic signature, which is very difficult to eliminate; it is almost impossible for a human translator to replicate the exact same wording.
TTN TMS can integrate numerous large language model (LLM) and machine translation (MT) engines. It runs hundreds of tests and calculates various comparison metrics, such as the number of revisions, revisions per line, Levenshtein distance, Jaccard index, BLEU score, and cosine similarity index. It then ranks the output according to quality. The results clearly show that AI translations improve significantly when generated with the support of a translation memory and a termbase.
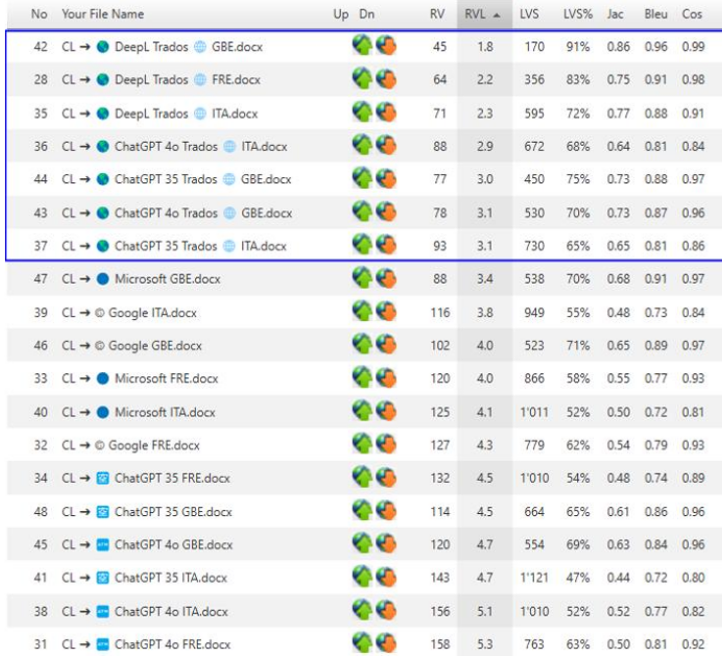
Figure 2: MT providers ranked by multiple comparison metrics
Figure 3: Continuous quality benchmarking against human translation
TTN TMS tracks the number of changes made by the human reviser and measures the time taken, compared to a traditional translation.
Term Extraction
The term extraction tool is an important component of the system; it is valuable not only for traditional translators, but also for producing terminology-aware AI translations. TTN TMS allows users to extract terms from translation memories, websites, or large file repositories. The translator or translation manager can choose from a wide variety of extraction tools that suggest translation candidates from parallel corpora.
TTN TMS integrates a range of extraction engines and services, including:
- Rainbow Term Extraction
- TBXTools
- tm2tb (Translation Memory to Termbase)
Smaller parallel corpora may also be extracted using ChatGPT 5.0. It can connect to Azure Cognitive Services – Key Phrase Extraction, a cloud-based solution by Microsoft accessible via a C# SDK. It is a commercial service. TTN TMS incorporates NuGet packages for Stanford CoreNLP to enable POS (part-of-speech) tagging and to use pretrained models. Stanford CoreNLP comes with pretrained segmentation models for both Chinese and Arabic.
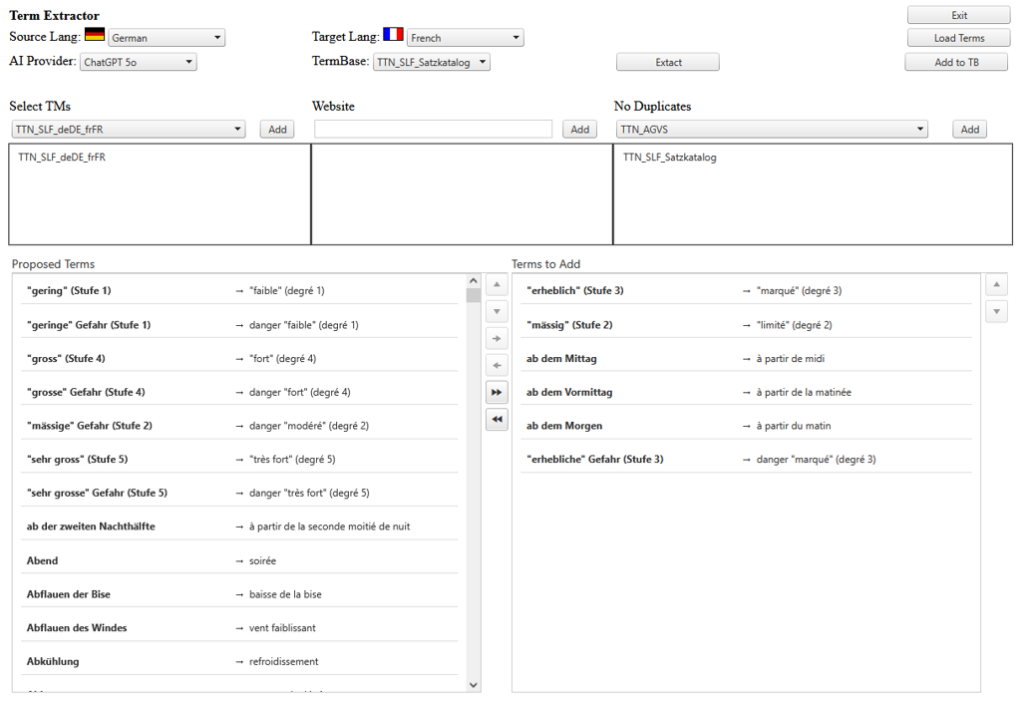
Figure 4: Term extractor with proposed terms to be added to MultiTerm database
Users can review ranked candidates, filter by frequency, length and domain, and drag terms from the proposed list to the final list—or accept all in a single action. Approved entries are normalised (e.g. case and morphology), de‑duplicated, and written straight to the MultiTerm termbase.
The term extractor accelerates onboarding for new linguists, improves consistency across projects, and reduces rework by enforcing approved terminology at source. By feeding validated terms back into Translation Memory and AI pipelines, it optimises MT output and raises overall translation quality. Centralised curation strengthens terminology governance, ensures traceability, and enables rapid reuse of domain‑specific terms across language pairs and programmes.
Terminology Synchronisation with AI Providers
Terminology (for example, DeepL glossaries) is automatically synchronised. After synchronisation, the automatic translation achieves a much better score.
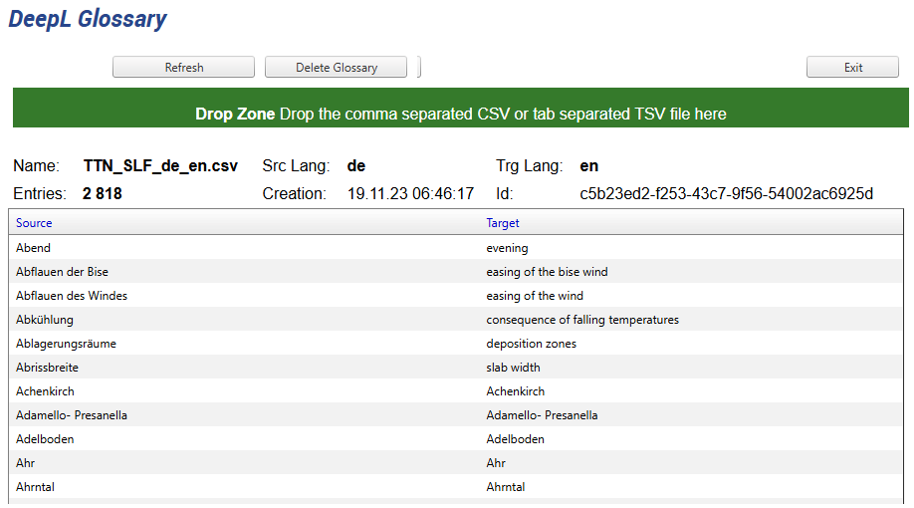
Figure 5: Automatic synchronisation between MultiTerm and DeepL glossary
The user can supervise the synchronisation process and delete any new glossaries on DeepL, but usually no human intervention is necessary.
Web-to-TM
In 2006, TTN TMS launched its own translation search engine called Keybot. This tool crawls the web at high speed to harvest multilingual content, creating a parallel database for each multilingual domain it encounters. It can also process large document repositories by aligning bilingual files, thereby generating extensive parallel corpora from existing translations.
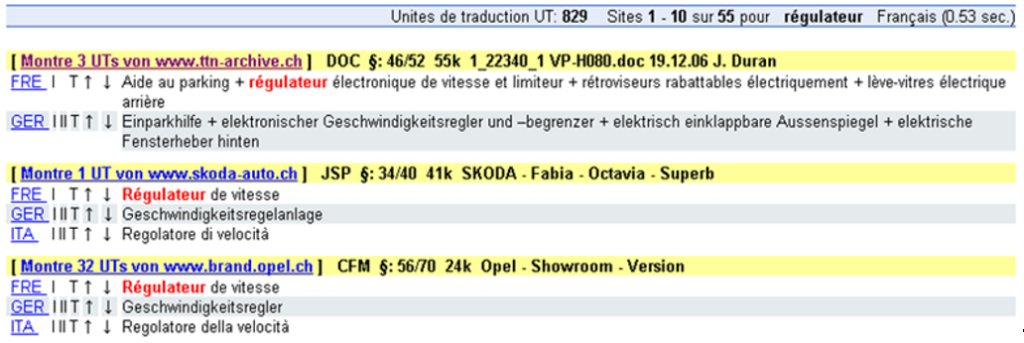
Figure 5: Client-specific parallel corpora for each client website
The Keybot search engine detects subtle differences in terminology across client websites, reinforcing confidence in the TTN system. When a client starts working with TTN, the system already recognises customer-specific wording, which can be immediately reused by converting existing parallel corpora into translation memories on the GroupShare server.
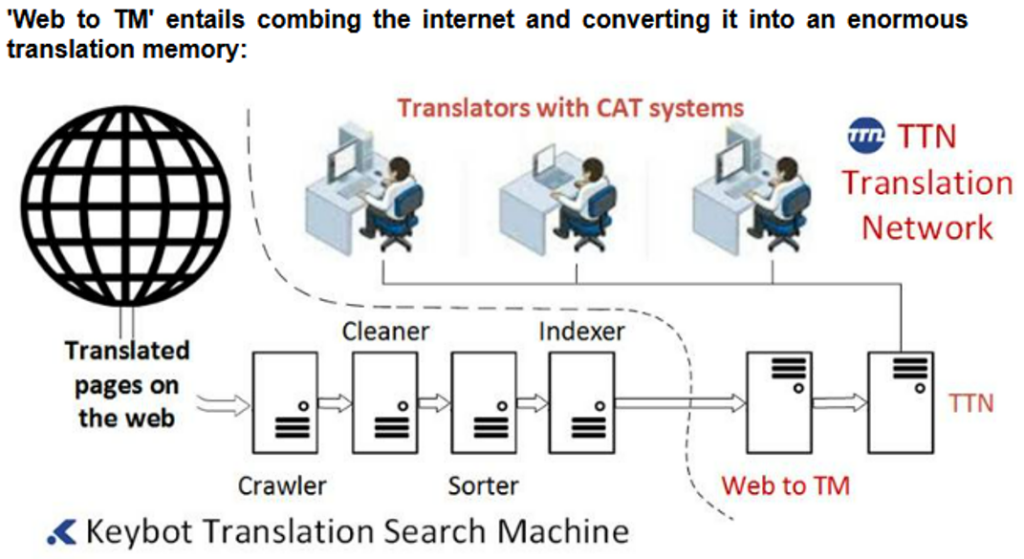
Figure 6: Web-to-TM converts entire websites into TMs
To find translated websites, Keybot uses high-performance web crawlers that traverse sites and extract translated text. The system automatically pairs source and target language content, converting entire pages into large parallel corpora. These crawlers efficiently identify matching texts across languages, ensuring that no translated segment is missed.
Figure 7: High-performance crawlers extract translated text from the web
The web crawler maintains a separate parallel corpus for each domain it scans, effectively capturing the site’s complete bilingual content.
Figure 8: Automatic integration of Keybot TMs during project generation
Once the parallel texts are extracted and aligned, they are converted into Translation Memories (TMs) and published directly to the GroupShare server. These TMs are then automatically added to each new translation project. In practice, this means translators have immediate access to vast amounts of high-quality translated content relevant to their project. The TM data serves as a valuable reference, allowing linguists to reuse proven translations and maintain consistency without any manual setup.
Thanks to Web-to-TM, TTN TMS enables organisations to leverage the full linguistic potential of the internet. The platform can automatically identify and align multilingual websites – even for domains where no prior TM exists – and turn them into rich translation memories. This dramatically accelerates translation projects, ensures consistency in terminology and style, and reduces translation costs through maximal reuse of existing translations.
With Web-to-TM, entire collections of documents – such as annual reports, status reports, contracts, technical standards, regulatory frameworks, and complete catalogues – are aligned and indexed. The result is a comprehensive, always-growing linguistic knowledge base that continuously improves translation quality and efficiency across the organisation over time.
Furthermore, translation memories produced by Web-to-TM can directly enhance AI-driven translation systems. Integrating a TM with modern AI translation engines yields more consistent and accurate automated translations. The AI can leverage the high-quality, human-verified translations in the TM to guide its output, avoiding the inconsistencies often seen in raw machine translation. In fact, studies have shown that using existing TM content alongside generative AI models can significantly boost translation quality – one experiment reported up to a 20-point increase in BLEU score after supplying the AI with relevant TM examples. In essence, combining AI translation with robust TMs offers the best of both worlds: the speed and scale of machine-generated translation, and the accuracy and reliability of human-curated translations. This synergy allows organisations to scale global communication without sacrificing quality.
AI Quality Check
Whether a translation is produced manually or via a machine translation engine, both the translator’s initial version and the proofread version of the text undergo an AI-based quality check. This process currently leverages a cutting-edge AI system to achieve the best results in reviewing translation quality.
As part of the AI quality check, the system sends individual segments from the XLIFF files to an AI service for evaluation. The AI reviews each segment for accuracy, grammar, spelling, terminology consistency, and overall linguistic quality. If the AI identifies any issues, it records them in a report table with references to the corresponding segment in the XLIFF file.
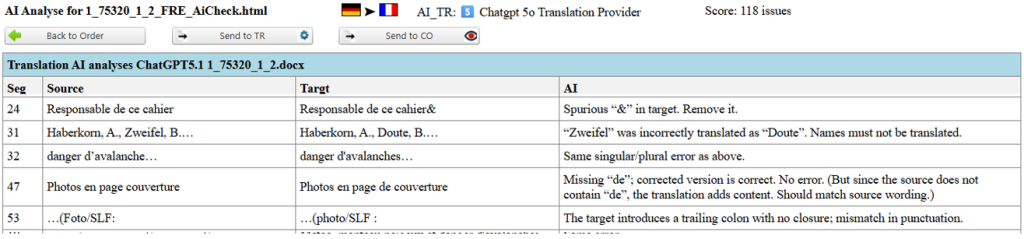
Figure 9: Reported issues from the AI Quality Check
This AI-driven check often highlights errors that human reviewers might overlook. For instance, a common issue with certain machine translation engines such as DeepL is the literal translation of proper names. Names like “Baker,” “Fisher,” “Cooper,” or “Turner” might be translated as ordinary words in the target language instead of being recognized as names. Similarly, place names such as “Hill,” “Wood,” or “Brook” can be mistranslated word-for-word. For example, Greenpeace may be rendered by DeepL as la paix verte in French or grüner Friede in German. The system effectively performs an automated double-check, detecting such errors and flagging them for review. However, it is important to note that many issues flagged by the AI are false positives or minor stylistic suggestions that do not require any change.
In practice, the system generates an AI quality report after the translator completes the initial translation. This report is then forwarded to the proofreader, who reviews the flagged items and addresses any valid issues while disregarding incorrect or irrelevant suggestions. After the proofreader uploads the revised translation, the AI quality check runs again on the updated content. The system recognizes which previously reported issues have been resolved and omits them from the new results, reporting only any remaining or newly detected issues. By the end of this iterative process, the translation manager receives a final, concise report of outstanding issues and can quickly verify if any problems still need attention.
The AI quality check provides an effective safety net for quality assurance. It often catches minor but critical errors such as typos in headings or front matter, mistakes with proper names, or omitted words. This additional automated review serves as an important safeguard, helping to prevent errors in high‑stakes documents such as important contracts or published materials that could have been missed without this extra layer of quality control.