TTN CAT Container Software
Computer-assisted translation container
Keybot Translation Search Machine
saugt mehrsprachige Seiten aus dem Web ab und bildet einen riesigen
Sprachkorpus in dem bis zu 165 Sprachen parallel abgespeichert werden. Die
indexierten Textbausteine sind im Web über www.keybot.com abrufbar. Dank der innovativen
Web-to-TM Technologie werden die Übersetzungsbausteine in gigantische Über¬setzungs-speicher (TM) umgewandelt, die von
Übersetzern mit CAT-Tools angezapft werden können. Die Konversion in TMs
erfolgt kundenspezifisch und es können komplexe Internetauftritte mit Tausenden
von Katalogseiten in einen CAT-Container eingespiesen werden. Die TTN CAT
Container Software bildet dabei die Brücke, mit der der proprietäre CAT-System
wie Trados, MemoQ und OmegaT bedient werden.
Warum braucht es ein CAT-Container?
TTN arbeitet
mit spezialisierten Übersetzern rund um den Globus zusammen. Die meisten
Übersetzer bearbeiten nur eine einzige Sprachkombination und ein enges
Fachgebiet, dessen Materie und Terminologie sie genau kennen. Sie sind als
Freelancer tätig und übersetzen oft nur gelegentlich für TTN. Das von TTN in
ihrem Spezialgebiet akquirierte Übersetzungsvolumen ist in vielen Fällen zu
klein, um alle Übersetzer zum Gebrauch eines einheitlichen CAT-Systems zu
zwingen. Das Gros der Übersetzer betrachtet das eigene System als das Beste,
und es ist schwierig, sie zur Umstellung auf eine einheitliche Software zu
bewegen. Die meisten CAT-Softwarelizenzen sind teuer und die Benutzeroberfläche
der Programme extrem kompliziert, so dass die Übersetzer wegen eines kleinen
Auftrags nicht von einem Tag auf den anderen auf ein vorgeschriebenes System
umstellen möchten.
So kommt es,
dass die Übersetzungen für ein und denselben TTN-Kunden mit verschiedenen
CAT-Systemen wie SDL Trados, MemoQ, DéjàVu, Wordfast, OmegaT usw. produziert
werden. Jede Software verwendet eigene Standards, so dass die Zusammenführung
der Übersetzungsspeicher (TMs) und Wörterbücher in der Vergangenheit schwierig
oder fast unmöglich war, obwohl alle Systemhersteller von sich behaupten, dass
ihre Daten mit den TMX- und TBX-Standards kompatibel sind. De facto war eine
Zusammenführung der Daten viel zu aufwendig und nicht in einem vernünftigen
Kostenrahmen zu bewältigen. Vor allem bei kleinen Aufträgen, die in 20 oder 30
Sprachen übersetzt werden mussten, kam es regelmässig zu Problemen, weil ein
jeder seine eigene Suppe kochen wollte und es unmöglich war, wegen ein paar
Zeilen 30 Übersetzern und 30 Korrektoren ein einheitliches System
vorzuschreiben.
Diese
Vielfalt von Insellösungen führte zu Problemen bei der Übersetzungsqualität und
in vielen Fällen zu höheren Produktionskosten, weil die an unzähligen Orten
verteilten Segmente und Wörterbucheinträge nicht recycelt werden konnten. Vor
allem bei Kunden, die hohe Ansprüche an eine einheitliche Terminologie und eine
homogene Wortwahl stellen, wirkte sich die Produktevielfalt im CAT-Bereich
negativ aus; es kam immer wieder zu Abweichungen von den Kundenvorgaben.
Zusätzliche Probleme traten dann auf, wenn Übersetzer und Korrektor nicht die
gleiche Software benutzten. Der Übersetzer legte seine «schmutzigen» Segmente
im Übersetzungsspeicher ab, der Korrektor pflegte seine Korrekturen in der
unsegmentierten Word-Datei ein, so dass die Speicher nachher nicht automatisch
aufdatiert werden konnten. Die Speicher verschmutzten schnell, und viele
Übersetzer wollten diese nicht mit ihren Kollegen teilen, weil sie sich vor
deren Qualitätsmängeln fürchteten. Schlussendlich arbeitete jeder egoistisch
mit seinem eigenen Speicher, wodurch der bei den grösseren Kunden erwünschte
Synergieeffekt unterblieb.
Um diesen
gordischen Knoten zu lösen, entwickelte TTN mehrere Jahre lang einen
CAT-Container, der beliebige Systeme aufnehmen kann. Das neue Meta-CAT System
automatisiert den Datenabgleich und ermöglicht es den Benutzern verschiedener
Systeme, problemlos miteinander zusammenzuarbeiten, ohne dass Daten oder
Korrekturen verlorengehen.
Das System
integriert unter anderem hyperschnelle SDL-GroupShare- und MemoQ-Server, die in
einem Hochsicherheitszentrum von Swisscom in Genf untergebracht sind. Diese
Server sind direkt mit dem Glasfaserkabel des Internet-Backbones verbunden.
Modernste 40-GB-Switch-Technologie ermöglicht einen fast unbeschränkten
Datendurchsatz.
SDL Trados und seine Grenzen
Trados wurde
1984 in Stuttgart von der gleichnamigen Übersetzungsagentur lanciert und 2005
vom britischen Konkurrenten SDL übernommen. Es ist ein historisch gewachsenes
Programm, dessen Anwendung zum Teil unnötig kompliziert ist. Es hat nach
eigenen Angaben einen Weltmarktanteil von 70 bis 80 % (ursprünglich 90 %). SDL
Trados wird vor allem von MemoQ konkurrenziert, das seinen Marktanteil in den
letzten Jahren schnell ausbauen konnte. MemoQ hat einen Entwicklungsvorsprung
von zwei bis drei Jahren, der für SDL Trados nur schwierig einzuholen sein
wird, da die von SDL Trados genutzte GroupShare-Serversoftware auf Silverlight
basiert, ein Produkt, dessen Support Microsoft ab 2021 einstellt.
Die mit SDL
Trados generierten Aufträge können entweder als Paket vom TTN-Server
heruntergeladen oder direkt auf dem GroupShare-Server von TTN ausgeführt
werden:
-
Bei der Generierung eines Pakets
werden die im zentralen Speicher gefundenen Übersetzungseinheiten in einen
projektspezifischen Übersetzungsspeicher geladen, der zusammen mit
zweisprachigen XLIFF-Dateien zu einer einzigen SDLPPX-Datei komprimiert, sodann
an die Übersetzer und darauf an die Korrektoren geschickt wird. Nach Abschluss
ihrer Arbeit senden die Mitarbeiter ein Studio-Rückpaket. Mit der letzten
Version des Pakets wird der zentrale Speicher aufdatiert, dessen Einheiten dann
für den nächsten Auftrag bereitstehen.
-
Für die Übersetzung via GroupShare
erhalten Übersetzer und Korrektoren einen Link in der Auftragsmail. Beim
Anklicken öffnet sich Trados Studio, und die XLIFF-Dateien werden vom GroupShare-Server
heruntergeladen. Projektspezifische Übersetzungsspeicher sind nicht nötig, da
die Übersetzungseinheiten direkt via Internet aus dem zentralen
Übersetzungsspeicher abgerufen werden.
Das
Bearbeiten der Aufträge via GroupShare hat den Vorteil, dass bei der
Konkordanzsuche der gesamte Speicher abgesucht werden kann, der mehrere
Millionen Übersetzungseinheiten umfassen kann. Im einen Paket hingegen stecken
immer nur die gerade gefundenen Einheiten, weswegen die Konkordanzsuche wenig
Sinn macht. Wesentliche Vorteile bietet GroupShare auch bei der Arbeit mit
Online-Wörterbüchern. Die IATE-Terminologiedatenbank beansprucht mehrere
Gigabyte Speicherplatz und kann unmöglich in einem Paket heruntergeladen
werden. IATE und Termdat enthalten die offizielle Terminologie der Europäischen
Union und der Schweizerischen Eidgenossenschaft. Die Verwendung der in diesen
Datenbanken gespeicherten Terminologie ist bei vielen Kunden zwingend.
Bei SDL
Trados benötigt der einzelne Übersetzer eine Lizenz für die Studio-Software und
TTN benötigt pro Verbindung mit GroupShare je eine Lizenz. Für den Fall, dass
bei TTN gleichzeitig mehrere Aufträge mit 20 oder 30 Zielsprachen eingingen,
wäre unser Lizenzpool schnell überfordert, was dazu führen würde, dass ein
Übersetzer nicht auf die Online-Ressourcen zugreifen kann. Zusätzlich zu diesen
sogenannten CAL-Lizenzen verlangt SDL Trados eine Grundgebühr pro Million
Übersetzungseinheiten. Letztere Gebühr führt dazu, dass wir allen neuen
Übersetzern vom Kauf von SDL Trados abraten. Ab 2017 werden mit der TTN-eigenen
Übersetzungssuchmaschine Keybot gigantische Übersetzungsspeicher generiert, die
unter anderem einen grossen Teil der übersetzten Webseiten der Schweizerischen
Eidgenossenschaft und der Europäischen Union enthalten werden. Das Einspeisen
dieser Daten in die SDL-Trados-Speicher wäre unter den gegebenen
Lizenzbedingungen viel zu teuer, deshalb empfehlen wir den Übersetzern, auf
MemoQ umzusteigen.
CAT-Container: Sprachmotor von TTN
Translation Network
Rund 80 %
der Aufträge werden online aufgegeben. Der Kunde wählt die zu übersetzende
Datei und die Zielsprachen aus. Das TTN-System berechnet die Fristen und Kosten
und schlägt dem Kunden mehrere Optionen vor.
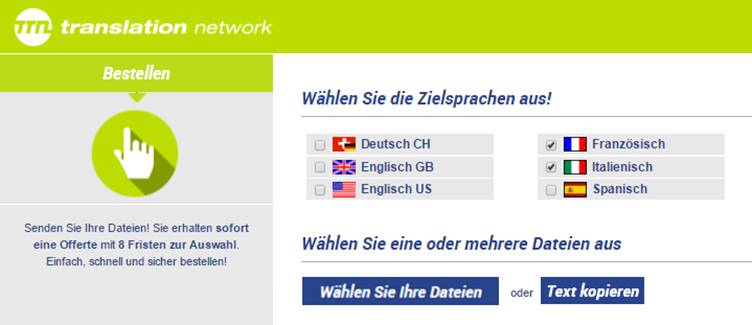
Jedem
Kundenkonto werden ein oder mehrere Übersetzer zugeordnet. Das System berechnet
die möglichen Fristen aufgrund der Verfügbarkeit der einem Konto zugeteilten
Übersetzer. Alle Übersetzer sind in einer Datenbank registriert, welche die
Arbeitszeiten und die Auslastung verwaltet.
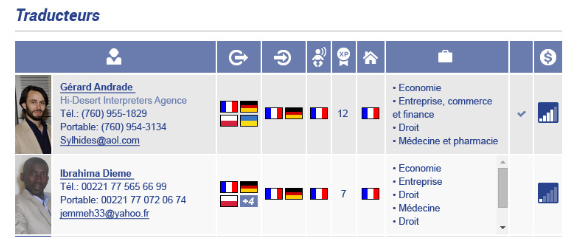
Lädt der
Kunde mehrere Dateien nacheinander hoch, werden die angebotenen Fristen
zunehmend länger. Dieses System erlaubt eine optimale Auslastung der
Übersetzer. Falls der Kunde eine kurze Frist wählt, und der Übersetzer am
Wochenende arbeiten muss, wird er mit bis zu 60 % Zuschlag entlohnt.
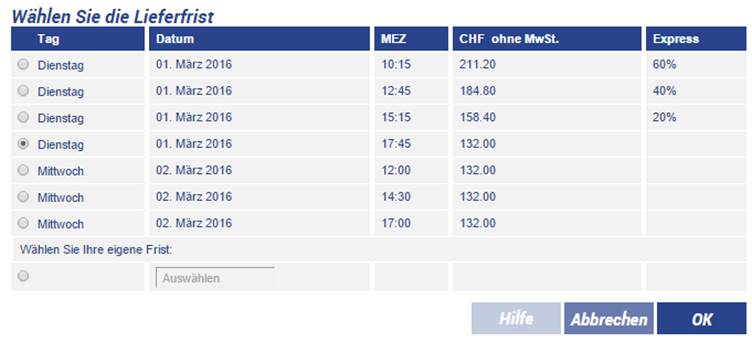
Nachdem der
Kunde auf OK geklickt hat, geht der Auftrag auf den TTN-SDL-Trados-Server, der
ein Paket generiert und den Auftrag in den SDL-GroupShare-Server einspeist.
Das
Verfahren läuft vollautomatisch ab. Die durchschnittliche Auftragslänge hat
sich in den letzten 10 Jahren um mehr als 50 % gesenkt. Die Aufträge der Kunden
werden immer kürzer, und sie möchten auch Kleinstaufträge, die nur ein paar
Zeilen einer Webapplikation umfassen, zu günstigen Preisen von einem
professionellen Übersetzungsteam bearbeiten lassen. Für viele Kunden musste TTN
aus Konkurrenzgründen den Minimaltarif ganz abschaffen. Das ist nur möglich,
wenn die CAT-Integration vollautomatisch funktioniert.
Die Kunden
des TTN werden in Archivgruppen eingeteilt, wobei eine Archivgruppe
normalerweise alle Personen einer Firma oder einer Organisation umfasst. Damit
es sich lohnt, eine Archivgruppe, eine Vielzahl von CAT-Speichern oder mehrere
Terminologie-Datenbanken anzulegen, muss ein neuer Kunde ein gewisses Potential
aufweisen. Für Gelegenheitskunden oder Privatpersonen, die nur eine
Scheidungsurkunde oder Ihr CV übersetzen möchten, wäre der Aufwand viel zu
hoch. Bei einem neuen Kunden werden deshalb die Übersetzungen zuerst im
TTN-Common-Speicher abgelegt. Das TTN berechnet aber für jeden Kunden laufend
die Anzahl übersetzter Wörter, und sobald ein Kunde ein gewisses Auftragsniveau
überschreitet, wird für ihn oder seine Firma eine eigene Archivgruppe angelegt.
Es liegt dann
beim Translation Manager, ob er die bereits vorhandenen XLIFF-Dateien
nachträglich im neu angelegten Speicher indexieren will.
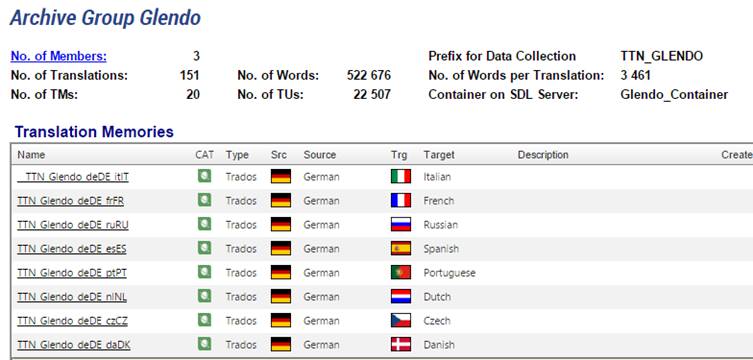
Eine
TTN-Archivgruppe entspricht einem Organisationscontainer auf dem
SDL-GroupShare-Server.
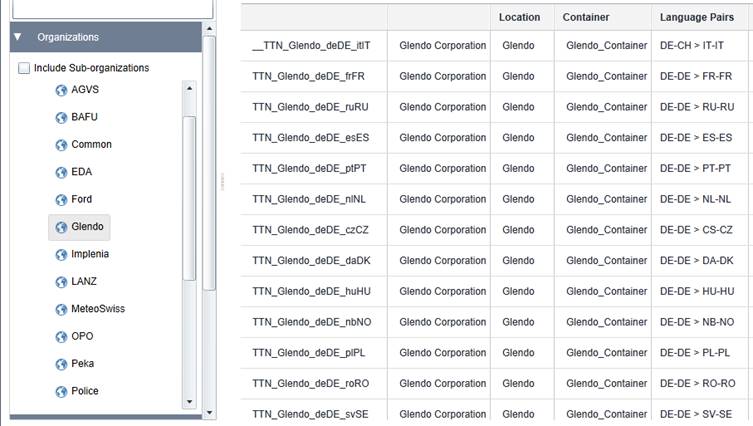
Ein Abbild
dieser Struktur wird auf dem MemoQ-Server generiert. Ein Kunde kann so über
mehrere hundert Übersetzungsspeicher verfügen, die alle automatisch angelegt
werden. Für jede Sprachrichtung wird ein eigener Übersetzungsspeicher (TM)
angelegt, es kommen keine TMs mit mehreren Sprachkombinationen zum Einsatz. Die
Aufteilung der Speicher in sprachliche Subversionen hat sich nicht bewährt:
Deutsch für die Schweiz oder Französisch für die Schweiz wird als DE-DE und
FR-FR registriert, damit die Speicher mit anderen Systemen kompatibel bleiben.
Die gleiche Bemerkung gilt für MultiTerm-Datenbanken, bei denen ebenfalls auf
Subsprachversionen verzichtet wird.
Sobald ein
Korrektor ein Paket hochlädt, schickt der TTN-SDL-Trados-Server alle Segmente
und Wörterbucheinträge an den TTN-MemoQ-Server und umgekehrt. Dank dieser
Synchronisation können alle Übersetzer auf die gleichen CAT-Ressourcen
zugreifen, wodurch ein optimaler Synergieeffekt entsteht.
In der
Betaphase wird das System mit MemoQ und SDL Trados getestet. Der CAT-Container
ist so konzipiert, dass mit wenig Aufwand andere Systeme integriert werden
können. Die Servertechnologie ist ausserordentlich anspruchsvoll, und es ist
damit zu rechnen, dass mittelfristig nur vier oder fünf von den aktuell 15
Systemen überleben werden.
Ausblick
CAT-Programme
übersetzen nicht selbst, sondern sie unterstützen den menschlichen Übersetzer
bei seiner Arbeit. Im Gegensatz dazu erfolgt eine maschinelle Übersetzung
automatisch ohne Mitwirkung eines Humanübersetzers. TTN strebt eine Mischform
an, bei denen die maschinelle Übersetzung geprüft und vervollständigt wird.
In
Zusammenarbeit mit der ETH Zürich hat TTN ein Übersetzungssystem entwickelt,
mittels dessen Lawinenwarnungen automatisch übersetzt werden. Eine Untersuchung
der Universität Zürich belegt, dass dieses System zuverlässiger als
Humanübersetzer arbeitet. Übersetzungsfehler sind praktisch ausgeschlossen, und
die fremdsprachlichen Texte werden zeitgleich zum Original generiert, was bei
Warnsystemen besonders wichtig ist. Allerdings kann das System vorläufig nur
Texte in einem stark beschränkten Fachgebiet übersetzen, die mit einem
speziellen Editor redigiert werden müssen. Das Fenster unten zeigt die
temporale Deixis der Lawinenabgänge. Beim Assemblieren des Systems wurden die
einzelnen Sprachelemente von einem Übersetzer in eine idiomatische
Satzreihenfolge gebracht, so dass eine Art vorabgespeicherte
Konservenübersetzung entstand.
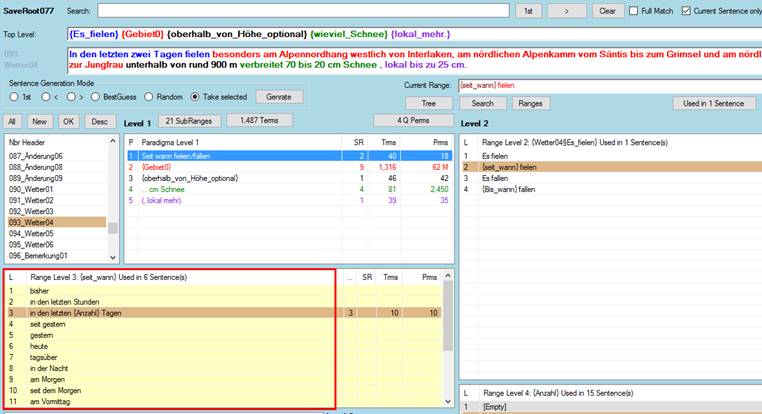
Während
Google Translate und alle anderen automatischen Übersetzungssysteme auf
statistischen Häufigkeiten aufbauen, basiert das neue System auf einer
syntagmatischen Segmentierung, die ursprünglich vom Genfer Linguisten Ferdinand
de Saussure entdeckt wurde. Diese verschachtelte Segmentierung ermöglicht es,
hierarchische Übersetzungsspeicher anzulegen, die im Hinblick auf die
Satzstruktur und die Übersetzungsgenauigkeit dem statistischen Ansatz weit
überlegen sind. Mit Hilfe eines klassischen Übersetzungsspeichers kann nur ein
einziger 100 %-Match gefunden werden. Hierarchische Übersetzungsspeicher der
zweiten Generation bringen hier einen entscheidenden Durchbruch: Sie können pro
Satz Abertausende syntaktisch und semantisch richtige Permutationen generieren.
Martin Bächtold, Keybot GmbH, Genf,
Mai 2017